记录下开发Chrome Extension的过程中遇到的问题和一些解决方案。
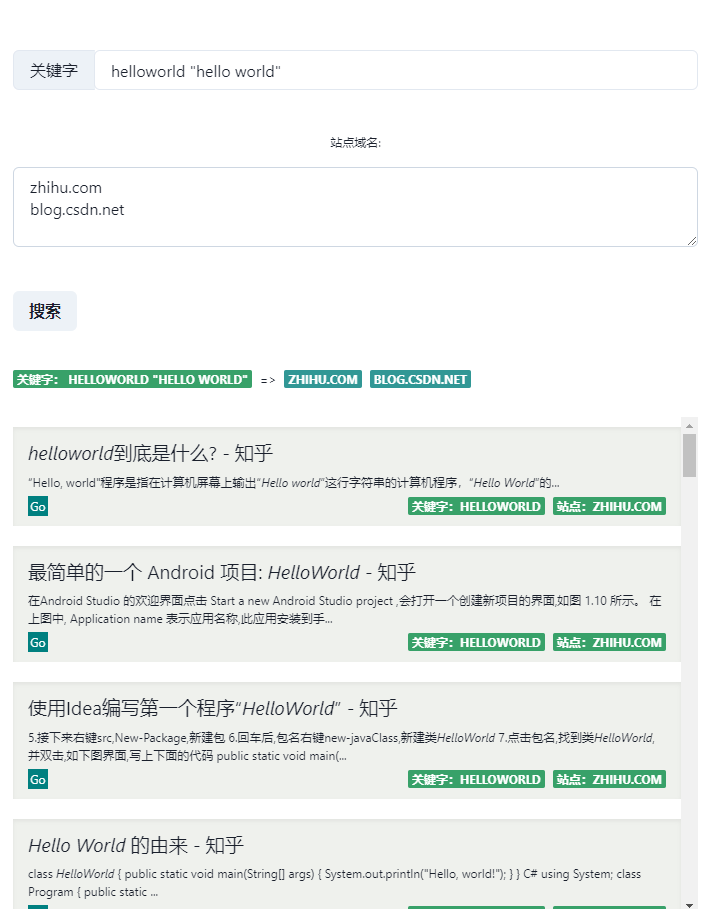
最近有一个需求,将关键字在多个用户指定网站中进行检索,但又不需要搞服务端和其他重量级的东西,因此尝试使用ChromeExtension + 百度”site”命令限定的方法简单的满足这个目的。
但由于百度对于页面收录时间有一定滞后性同时可能存在某些网站页面被限制收录或者无法收录,因此这种方法只能时说满足了一个简单的聚合搜索的一个需求,并不能作为一个对实时性搜索条件要求较高的软件。
由于我自己之前没有写过Chrome Extension,本来想直接用我经常使用的一个脚手架框架Nx进行修改然后用来进行monorepo管理,但是发现如果不进行自定义的Webpack配置文件编写,无法完成代码多个entry的包编译。
后面我又尝试了使用Nx将background(service worker)、popup、content-scirpt分到三个不同的项目中,而后使用Nx的custom-command对编译后文件进行复制、整合,尝试通过这种方式构建出一个比较智能的编译流程。
但上面这种使用Nx框架构建custom-command完成半自动编译脚本这种方式实现后,因为我不知道怎么构建Nx的watch服务,因此无法在fileChange的情况下进行自动编译,导致每次代码修改都需要将代码重新手动编译一遍,而且由于这种模式使用的事Nx框架构建的脚本命令,每次手动编译都需要Nx自己启动一次内部脚本代码,导致速度不是很快,使用起来体验不是很好。
这里感谢chibat/chrome-extension-typescript-starter repo,这个库是一个Chrome插件的boilerplate,我在尝试自定义Nx失败后就使用这个库提供的boilerplate完成这个插件的开发。这个模板项目使用Typescript + React + Webpack 作为插件编写的依赖,正好符合我的技术栈。
代码结构
由于使用的boilerplate,因此主要的代码结构还是模板提供的结构:
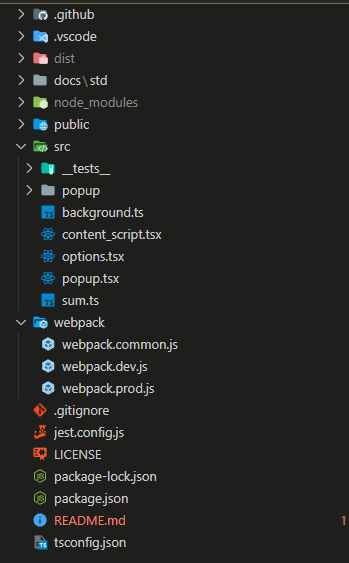
由于这里的代码结构都比较常规,我就不多赘述了。
Webpack配置
Webpack配置比较简单,这个配置文件主要由:
- 配置了多个Entry popup、options、background、content_script
- 输出与入口文件名同名
- 将public文件夹下文件复制到目标dist文件夹下
三个部分构成:
const webpack = require("webpack");
const path = require("path");
const CopyPlugin = require("copy-webpack-plugin");
const srcDir = path.join(__dirname, "..", "src");
module.exports = {
entry: {
popup: path.join(srcDir, 'popup.tsx'),
options: path.join(srcDir, 'options.tsx'),
// background: path.join(srcDir, 'background.ts'),
// content_script: path.join(srcDir, 'content_script.tsx'),
},
output: {
path: path.join(__dirname, "../dist/js"),
filename: "[name].js",
},
optimization: {
splitChunks: {
name: "vendor",
chunks(chunk) {
return chunk.name !== 'background';
}
},
},
module: {
rules: [
{
test: /\.tsx?$/,
use: "ts-loader",
exclude: /node_modules/,
},
],
},
resolve: {
extensions: [".ts", ".tsx", ".js"],
},
plugins: [
new CopyPlugin({
patterns: [{ from: ".", to: "../", context: "public" }],
options: {},
}),
],
};
这里由于我这个Chrome插件不添加Service Worker和 content-script,因此将此处的background.ts和content_script.tsx注释掉了。
这里需要注意的是,如果自建Typescript项目项写Chrome插件则需要安装@types/chrome,才能直接通过chrome namespace拿到Chrome Extension 的API。
功能及依赖分析
首先这个软件需要实现的功能是:
用户输入一个或一组关键字和一组被搜索域名,然后插件内部将通过百度的”site:”+被搜索域名 进行搜索,然后将搜索结果的第一页中包含的链接、摘要、标题信息抽取出来,并展示在插件搜索结果列表中。
总体来说这是一个非常简单的需求,这里我也没有使用过于复杂的技术栈,只是用了我比较常用的那一套:
- Nx Monorepo 管理框架
- React 18
- Chakra-UI + @chakra-ui/icon
- Framer Motion
编写历程
Popup方式
最开始,我感觉这个功能比较简单,因此就只是单纯的想把这个搜索的所有东西都直接在插件的popup上显示,但后来发现由于需要显示的文字过多(关键词数 * 限定域名 = 所需要显示的搜索结果,同时搜索结果中还有不定长的摘要文字,因此需要显示一个比较长的列表),同时Popup有最大长宽限制,因此直接在Popup中展示不是一个好的选择。如果后面有时间具体完善整个插件的逻辑和架构,可以尝试在插件的popup上显示一个类似于思维导图和树的形式,通过用户自己选择展开与否减小所需要占用的空间大小,这样应该就可以把所有的内容展示在一个popup上。
请忽略我demo的魔鬼配色和样式。
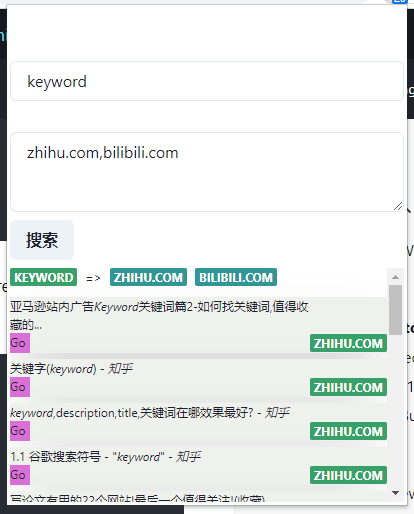
Options方式
由于popup的大小限制,在时间比较紧迫的情况下又不知道如何通过其他方式打开一个插件的页面,因此就直接使用ChromeExtension的Options页面作为查询页面。由于使用React编写,同时Chakra框架可以响应式的显示,因此直接将组件重新填充到Options中并简单调整了下格式就完成了这部分的编写。同时在插件的Popup页上仅留出了一个按钮,点击这个按钮就会自动跳转到Options页面中,并显示上一次的搜索结果。
这里上面两个输入框(Input和TextArea),上面的存储关键字组,下面的存储限定域名组。
这里只是一个简单的页面具体的代码就不贴了,而且其实调用的Chrome API 并不多:
Storage API
Storage方面API使用了chrome.local.get及chrome.local.set两个API对插件的状态进行保存,当页面被打开时,程序将从预设的ChromeStorage中取出暂存的数据,并反序列化为程序状态。另外当用户进行搜索并搜索成功时,程序的状态(包括搜索结果)将存储在对应key下ChromeStorage中。
Tabs API
由于需要跳转到对应URL,因此还是用了Chrome Tab方面的API,通过
Action API
这里使用Action API 中chrome.action.setBadgeText 设置插件右下角的红点标识,用于提示用户当前搜索条件下有多少条匹配的搜索结果。