本文用于记录在基于ReactFlow设计和实现Plugin-Centred节点流程图软件时的设计依据和原因。

动机
最近在构思爬虫引擎和平台时对一个爬取策略抽象之后发现所有的逻辑实际上是一组有前后依赖、有关联性的一组顺序流程节点,因此设计了一个简单的节点流程图插件架构。现在暂时所有的插件以同步内嵌的方式加载到平台上(说是平台,其实只有一个用于构建流程的页面),所有节点插件和架构infrastructure代码都打在一个bundle内,后续会将插件以插件中心注册,异步加载的方式进行分发和执行。
当前情况没有考虑插件安全性,仅能单纯作为Demo。
整体思路
首先我们来理清一下这个节点流程图的目的。由于当前应用场景是对数据的爬取,因此整个节点流程图在前端上由用户构建,但存储在后端,而后以某种频率、某种输入(包含该流程图的变量,例如账户,时间偏移量等)对流程图进行调用。该调用因以某单一节点出发,而后以深度优先算法执行其子孙节点(即以该节点输出做为输入的节点及其后续节点被称为子孙节点,即该节点为起始的子流程图)。同时子孙节点中某些具有流程控制特性的节点将影响其后节点的执行。
因此这里我们把整个流程图抽象出来就很明显了,其实就是一个函数,但这个函数是使用节点流的形式出现。每一个节点都是构成函数的一部分有效逻辑,其中节点主要分为两部分,一部分为流程控制节点,另一部分为资源操纵节点。流程控制节点可以根据输入而控制对其后续子孙节点的触发。数据操纵节点则是函数中对资源操纵的实际节点,这里的对资源操纵不仅包括对当前节点从父节点上接收的数据,同时还包括对网络、磁盘等资源操纵。
流程图执行的过程实际是对每一个节点执行的过程,相当于当前节点将上一节点输出数据进行数据处理的过程。整个流程图由某一初始节点出发,该节点将初始数据注入其子孙节点中,而后子孙节点以该输入数据为基础周而复始这个过程,直至所有节点都处理完(执行流触及到节点为Null)。
这里每一个节点所接受到来自上一个节点的数据被称为节点状态。而节点状态有几种实现方式:
- 所有节点状态共享,即所有节点都在一个作用域下对同一个状态数据进行操纵。
- 节点状态独立,即某节点输出的状态数据仅用于其子节点使用。
第一种写起来比较简单,在大数据量情况下这种方式实现可以提高性能。第二种节点状态独立需要在每次执行节点前将状态复制一份(或者COW),性能有一定影响,但对于整个流程图来说这种逻辑才更合理。
以上说明流程图的执行时因为这里的执行以代码实现其实是一个比较复杂的过程。首先有两种实现方式:
- 深度优先算法
- 广度有限算法
深度优先算法需要进入某节点时首先执行该节点,而后将其所有子节点入栈,而后出栈一个节点继续执行。直到栈空。
广度优先算法则需要进入某节点是首先执行该节点,而后将其所有子节点入队,而后出队一个节点继续执行。直到队空。
这里还需要注意有些节点可能是异步节点,需要等待异步数据,因此需要把这些异步节点放到额外的异步队列内(由于在执行该节点后就可以拿到节点执行数据,可以通过判断其是否为Promise类型来判断,如果是Promise则不将其子节点入栈\队),当超时或者结果resolve之后就可以从异步队列内拿到对应数据,而后将其子节点入队/栈。当然多输入的节点同样是这种方法,不过可能需要将这类当前不满足执行条件、结果的节点抽象为一个独立的结构来存储,但一个为等待输入,一个为等待输出,具体实现还要具体考虑。
上面讨论了这么多关于流程图整体的逻辑,现在该进入节点方面的逻辑讨论了。
节点
节点,在我的理解里是指对某一流程控制、数据操作以人类可理解的逻辑边界划分的一段相对独立的代码,这段代码必定有输入及输出。这里的输入输出不仅包括以连线方式出现的节点间的数据流转,同时包括来自用户的交互(点击等),对于节点外部环境的交互(控制台输出)。
而这段代码在UI上的展现形式即一个流程图节点,该节点可以表明其用途,同时可以通过某种方式对该节点的某些内部状态(配置)进行控制,以调整其逻辑达到用户预期。
以上说明仅为我个人理解,可能有失偏颇或错误,而我在后续学习过程中对概念理解更加深入后将会回来更新。
由以上对节点的定义我们可以知道两件事,节点至少有一种输入,至少一种输出,不然他就是一个逻辑孤岛`()=>void`纯函数,没有任何意义,因此下面来列举一下一些简单的节点:
- 触发节点
- 输入:用户点击触发按钮
- 输出:触发子孙节点执行
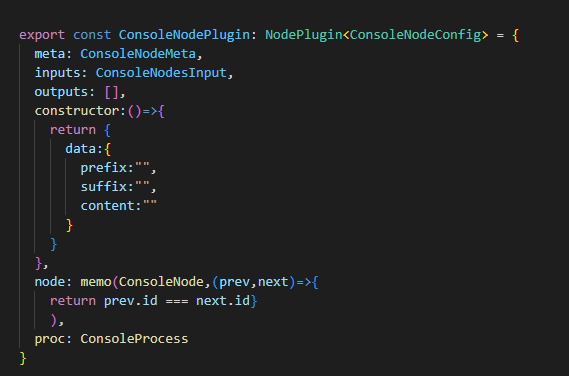
- 控制台打印节点
- 输入:上一节点数据输出
- 输出:控制台数据打印
- IF逻辑控制节点
- 输入:上一节点数据输出
- 输出:触发某一子流程图执行
因此这里我们可以将节点的一个形态画出来:

v0.1 wep 悄悄写个开头,到处挖坑不填