先贴一个任何人都看不懂的BrainStorm的草图:
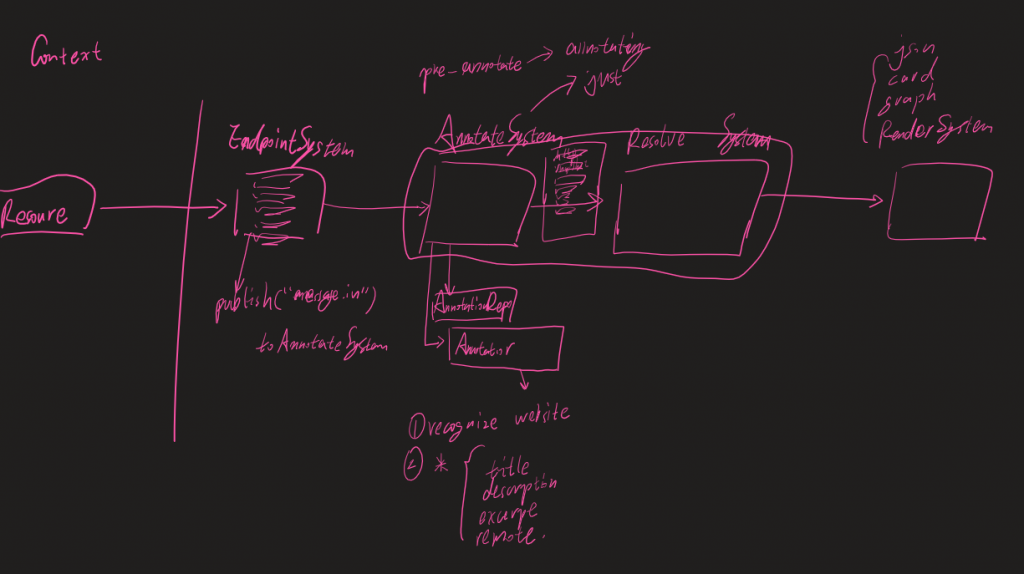
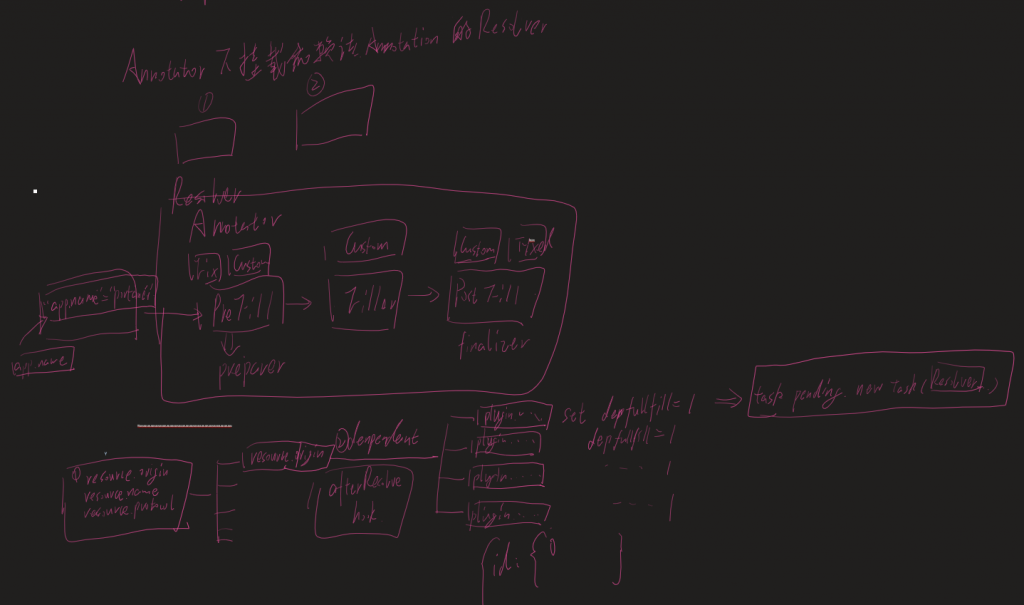
Annotation模块是LinkCat中最为重要的一部分,但由于现在LinkCat处于第一次功能设计和实现阶段,因此很多地方都有code smell。本文则是用于记录Annotation模块在当前版本v0.1下的设计,以便后续迭代可以有文字架构参考。
代码结构
当前版本中的Annotation模块还没有独立出去,以后这个模块将作为@linkcat/annotation 独立出来,然后可以直接挂在到@linkcat/core上运行,以实现以后规划的分布式架构(只有构想,代码里面是没有任何hint的)。
本文中所有 “注解模块”、“Annotation模块” “AnnotateService” 均指LinkCat v^0.x.x版本中默认注解模块。
定义
本节给出Annotation及其附属定义.
Annotation.Definition class
Annotation.Definition是Annotation命名空间下的一个定义类,这个类是Annotation的定义和元数据(浅显的参考RinWorld的架构)。在Plugins内使用builder进行定义的注解实际是在对这个类进行构建和填充。
export class Definition {
key = "";//注解的key:org.linkcat.github.repository,命名规范后面出文章将
static Separator = '&';//这个当注解stringfy时不同注解之间的分隔符,后面挪走
dependent?: [Resolver, DataProcessor][];//这个暂时没有使用,dependent被我挪到matcher系统内了
aliases: string[] = [];//注解human-readable的名称,比如 协议、来源等,后面写成localizeProvider用以支持不同语言
dup = 0;//这个暂时没用,这里是记录这个注解的解析器的duplicate数,还没有完全实现这个功能,只把resolver的priority写了
_value: Definition[] = [];//这里是注解的值,所有的注解都有至少一个注解类型的值,后面解释
description = "";//描述,需要改动
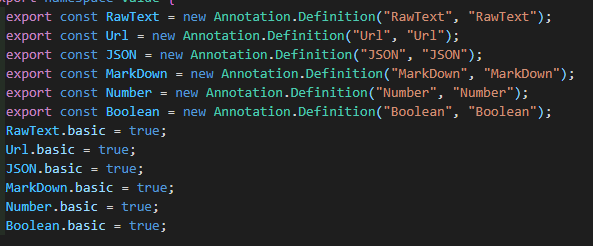
basic=false;//标志是否为基础注解,以非自定义注解为值类型的注解的值类型是basic=true的,例如RawText、Boolean、URL等
isValue=false;//标志是否该注解是某注解的值比如 linkcat.buildin.protocol=[linkcat.buildin.http,linkcat.buildin.https....]这里的http和https就是值类型注解
}
这里说明一下,LinkCat中所有注解的值也是一个注解,比如 isRead=true,则说明 isRead注解的值类型为 Annotation.BaseTypeAnnotation.Boolean。这里的Annotation.BaseTypeAnnotation是内置的primary注解集合。同时如果在定义注解时没有定义值类型,则默认值类型是Boolean类型,即存在该注解则为true,不存在则为false。
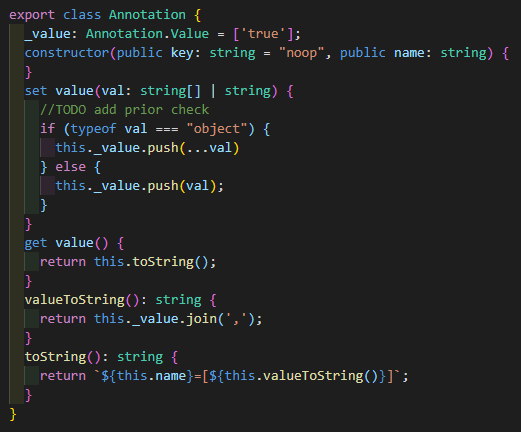
Annotation class
Annotation类其实是一个简单KeyPair类,这里没有直接存储指向其定义的指针,而是通过创建时传入的key来确定类型。一个很简单的类。_value是一个字符串数组,用于存储注解的值,因为
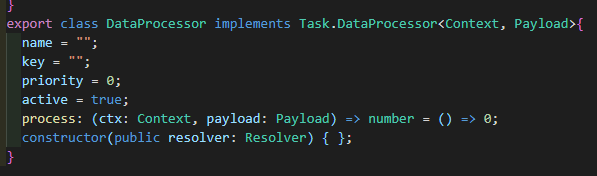
DataProcessor class
DataProcessor类是一个middleware-like类型的类,是进行Annotation数据处理的基础类。DataFiller、DataPreparer、DataFinalizer都是他的别名。在plugin内定义的数据填充函数就是他。
Scope class
scope类实际并不在Annotation模块中,而是在@linkcat/core Context部分中,但由于下文需要提到Scope类,所以这里需要进行简单介绍。
Scope是一个简单的Record类型,他的主要用途是用户在编写插件是定义的插件作用域,其中key是注解的key,value是用户对该注解的限制。比如说我想限制插件在github网站,同时需要用户开启定时抓取。
resource.origin=:protocol(http|https)/com/github/www/:AccountOrProject/:Repository;schedule.period.fetch=true
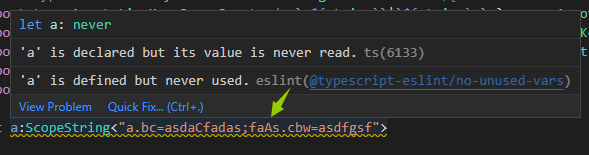
左侧resource.origin是限制资源来源,右侧则是检查schedule定时fetch开启状态。这就是一个Scope,不过是ScopeString状态下的Scope,在实际使用过程LinkCat会转换为KeyPair类型。如下图的Scope类型。
这里Dot“.”将AnnotationKey分割为了多部分,我们将这些字符段称为Annotation的域。resource.origin就有两个域。

这里其实可以加个简单的type check,仓促编写可能有没考虑到的边界条件:
export type LowercaseCharDictionary="a"|"b"|"c"|"d"|"e"|"f"|"g"|"h"|"i"|"j"|"k"|"l"|"m"|"n"|"o"|"p"|"q"|"r"|"s"|"t"|"u"|"v"|"w"|"x"|"y"|"z";
export type AnnotationKeyRec<S extends string> = S extends `${LowercaseCharDictionary|number|"."}${infer Rest}`? AnnotationKeyRec<Rest>:S extends LowercaseCharDictionary|number|"."|""?"":never;
export type AnnotationKey<S> = S extends `.${string}`|`${string}.` ? never:AnnotationKeyRec<S> extends never?never:S;
export type AnnotationString<S> = S extends `${infer K}=${infer V}`?AnnotationKey<K> extends never?never:V extends `${string};${string}`?never:S:never;
export type AnnotationStrings<S> = S extends `${infer A};${infer Rest}`?AnnotationString<A> extends never?never:AnnotationStrings<Rest>:AnnotationString<S> extends never?never:S;
export type ScopeString<T> = AnnotationStrings<T> extends never?never:T;
然后更新一下:

这样就可以对ScopeString进行简单的TypeCheck
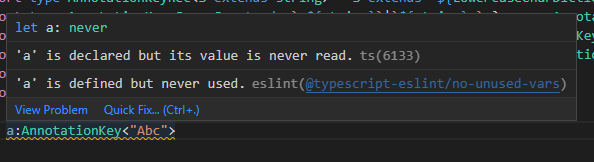
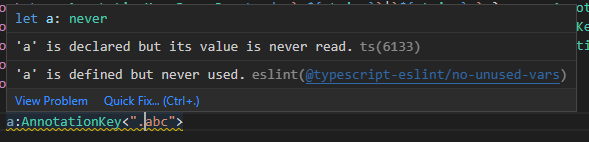
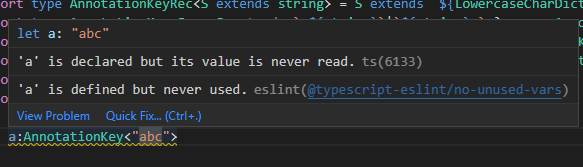
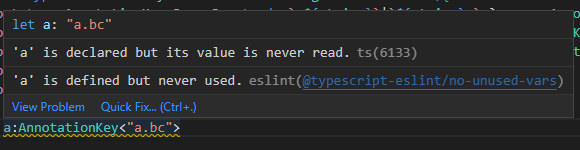
首先是AnnotationKey的判定,AnnotationKey是由“.”分段的小写字符+数字构成,收尾不可存在“.”:
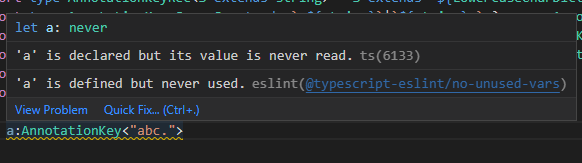
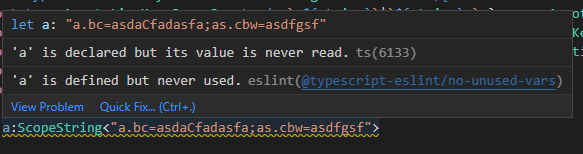
然后是整个ScopeString
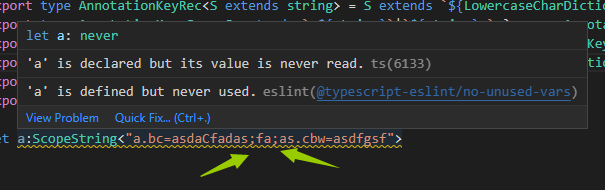
Scope在整个Annotation系统中位置非常重要,它是后面讲的Matcher系统的一个重要组成,同时对于插件启用匹配起决定性作用。
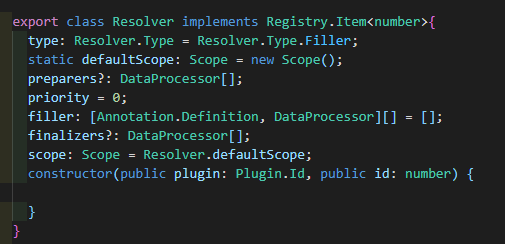
Resolver class
Resolver类是注解解析器,一个解析器下拥有三种类型的DataProcessor,而在插件编写时一个context.builder()到builder.register()过程就是把中间所有定义的preparer、filler和finalizer构建一个Resolver。而一个Resolver也是Annotation执行的最小单位。Resolver只会在设置的Scope下执行。
在插件的编写过程中:
- 使用builder.prepare()传入的是preparer,将在Resolver执行时最开始执行
- 使用builder.def()定义注解时,传入的第三个参数就是filler
- 使用builder.finalizer()传入的是finalizer
因为这里是类似三个不同优先级middleware array后面打算在不同Scope下加一些内置的解析器,比如将SideEffect的清除器(Puppeteer Page Disposal操作)。
Resolver在被注册后其中的DataFiller会根据其fill的Annotation在AnnotateService上的AnnotationDependents挂载,这里有很大的优化空间。比如根据域的首字母分一个树形结构,参考PathMatcher。

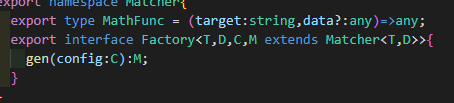
这里比较重要的是factory,这里的Factory实际上既是一个Matcher,又是一个MatcherFactory,他是在定义Annotation时通过matcher()函数传入的一个MatcherFactory,每当一个Resolver中的Filler被挂载其所属的Annotation下时,就会调用上图factory.gen函数,根据config将该filler注册进Matcher中。
resource.origin=:protocol(http|https)/com/github/www/:AccountOrProject/:Repository;schedule.period.fetch=true
Resolver的DataFiller执行的时机是由其Resolver的Scope决定的,还是以这个为例,当resource.origin被解析时,AnnotationDependents中resource.origin下挂载的factory就会将解析好的标签resource.origin=https/com/baidu/www使用内部的算法进行匹配。在定义注解时如果不传入matcher,默认会使用ExactMatcher,即完全匹配。而resource.origin是使用的为path match特化的PathMatcherFactory。

这里我们理顺一下注解的执行流程,首先是resource.origin这是priority最高的注解类型,注解模块会最先执行它(因为它只是单纯将资源来源转换为LinkCat中resource.origin这种路径形式而后填入,没有页面和其他操作)。而后在AnnotationDependents里去找resource.origin,而后执行factory.match()函数。
- resource.origin被填充他的scopestring=“*” 是一个wildcard
- AnnotationDependents[“resource.origin”].factory.match(payload) 这里的payload就是“https/com/baidu/www”形式的字符串
- 如果有哪一个filler的scope被匹配到了
- 填充这个Resolver在payload中对应的scope 可以看成payload.plugin.scope[“resource.origin”]=true //这里其实还会将path中variable填进去,比如上面的 :AccountOrProject :Repository
- 首先判断他的scope数量比如上面就有两个,一个是resource.origin一个是schedule.period.fetch
- 没有全部满足,不管他
- 满足所有scope,将这个Resolver的解析Task添加到AnnotateService的TaskLoop中(emm好像忘了讲TaskLoop,看了React源码之后才感觉和我这个有点像)。
AnnotationService中的TaskLoop
这里既然引入了TaskLoop,就讲一下AnnotateService 中的任务执行。

AnnotateService中任务的入口是一个middleware-like的函数,这里面就只有一个操作,将一个添加GeneralResolvers的Task到TaskLoop中,这里的GeneralResolver实际上就是在注册插件的时候使用context.on(“*”) wildcard的解析器,比如内置的resource.origin就是一个general resolver。

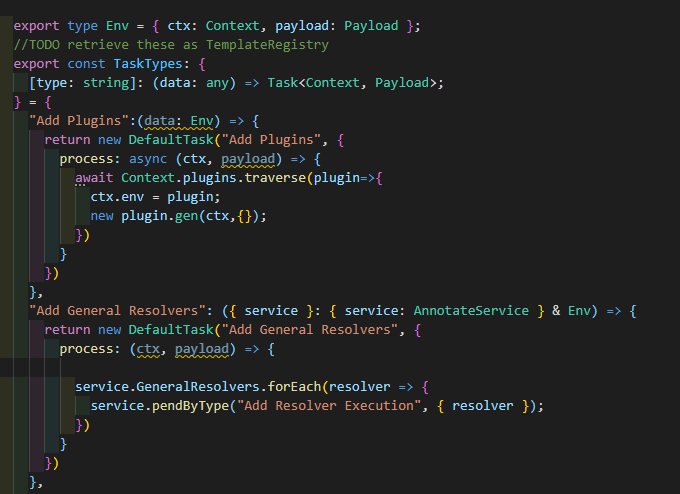
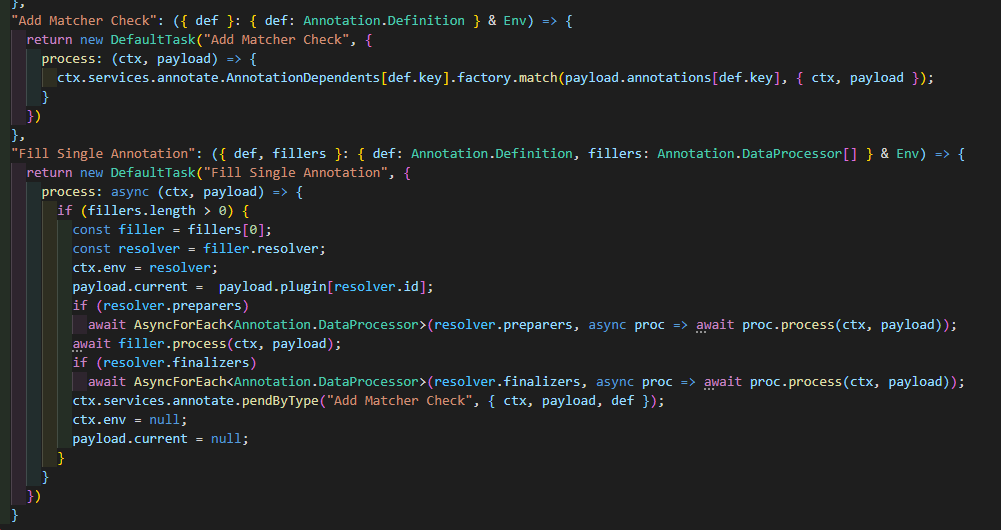
AsyncForEach是@linkcat/utils内一个异步forEach 工具类型的函数,保证整个foreach的async函数serilize同步化,后面会尝试添加Concurrent模式,因为每个Resolver实际上是对当前状态无感知的,而且NodeJS异步比C++简单太多,C++异步参考之前的文章:
这里的代码还比较vulnerable,后面准备设计把这些Service设计成另外一种结构,能够方便的更改其执行流程,比如check之类的。
再来整个执行流程,其实和Reactor模式有点像,在不断生成Task,直到整个Queue被消耗空。在看了部分React源码后,我打算把整个@linkcat/core设计成这种模式,仿照React reconciler来写,这样可以为LinkCat提供Schedule的能力。为以后CustomService和MicroServiceStyle提供基础支撑。
Matcher系统
上文中Matcher是一个对于整个AnnotateService是非常重要的,这里详细讲一下AnnotateService中的Matcher系统。
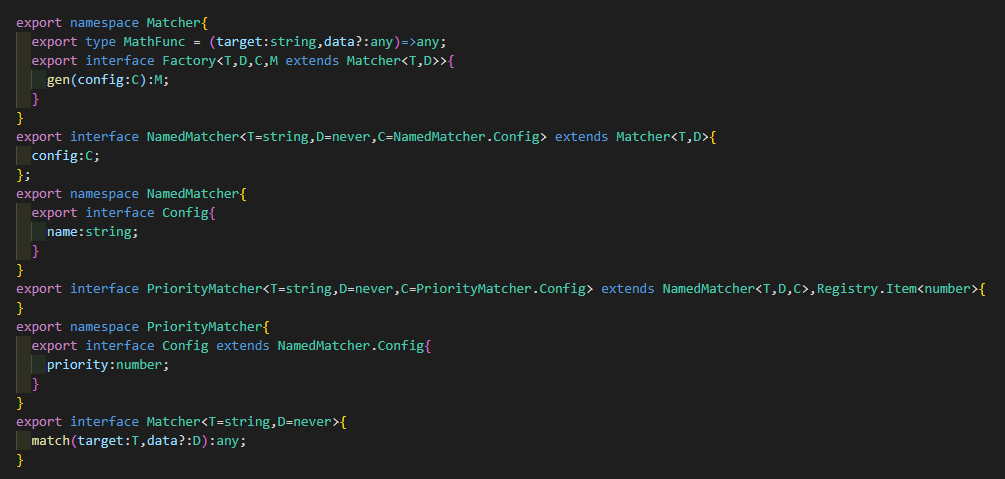
上图可以看到一个Matcher最为核心的是他的MatchFunc而@linkcat/core中实际是DefaultMatcherProto,这里的Config里面goal就是目标值,但是这里其实可以直接给个空串,因为实际代码实现是Matcher内部自己的操作。callback是如果match结果匹配成功时的callback。这里使用callback而不是直接返回结果是因为我不希望将这部分逻辑写死到每个Matcher的外部调用函数,而是通过一个callback执行用户代码。

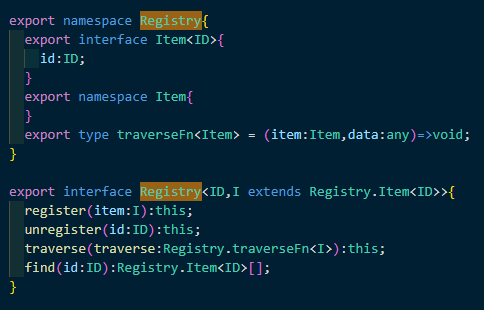
然后下面是MatcherFactory的继承链,这里的Factory除了自身是一个Matcher外,他还实现了MatcherRegistry,这样就可以拥有注册和管理Matcher的能力。


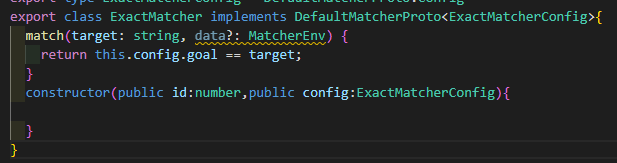
ExactMatcherFactory
ExactMatcherFactory是LinkCat默认提供一个MatcherFactory,他只会完全匹配注解的值。也就是说,只有注解值和目标值完全匹配才会执行对象Matcher中的Callback。下面是ExactMatcherFactory生成的Matcher,可以看到非常的简单。就是判断字符串是否相等。
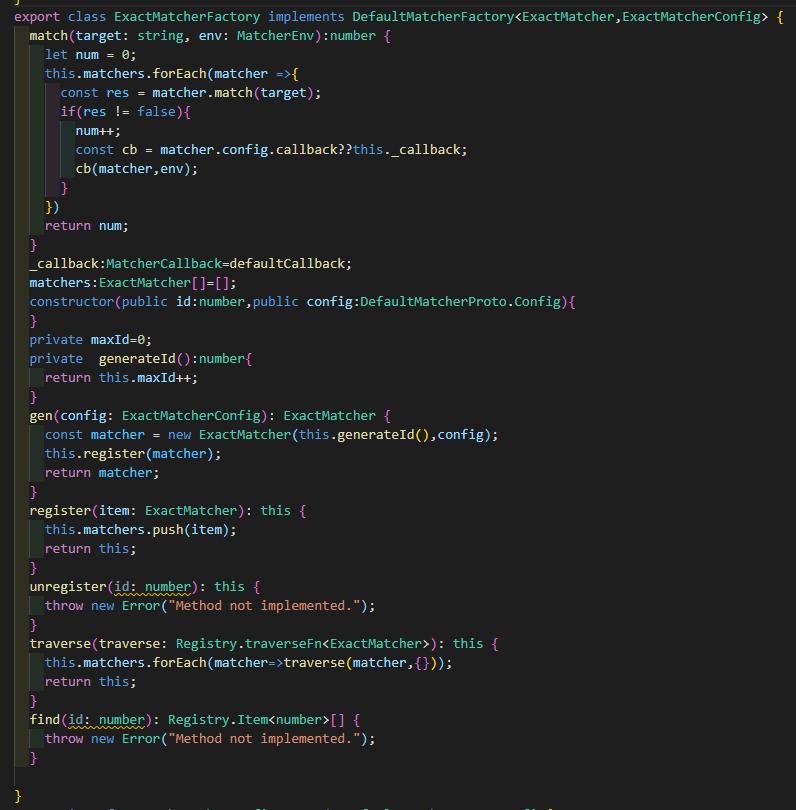
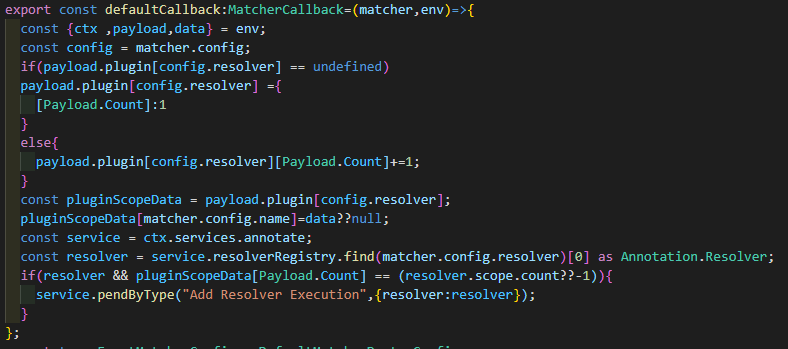
这里需要注意的是这个Factory内部有一个_callback,这是用于存储当Matcher内部的callback没有定义时所调用的默认回调函数。下面是这个函数的执行逻辑。其中可以看到实际上就是一个对Scope的判定逻辑,如果满足所有Scope就将Add Resolver Execution Task给pend上去,没有满足就单纯更新一下payload.plugin对应resolver的scope。emm code smell。后面再重新考虑下,将整个Scope的逻辑抽象出来构成一个独立的ScopeSystem,方便后面拓展。
ExactMatcherFactory中所有的Matcher都是顺序存储,因此他会一个一个去匹配,这里还有很大的优化空间。下面是MatcherFactory进行匹配的时机,可以看到这是个Task,这个Task只有在某一个Annotation被成功解析时才会执行。内部也很简单,从AnnotateDependents里面找到对应的Factory,然后使用match函数。

到这里整个AnnotateService的逻辑就比较清晰了:
- 1.添加General Annotation Resolver Task
- 2.执行GeneralAnnotationResolverTask
- 2.1添加所有GeneralResolver的AddResolverExecutionTask
- 3.执行AddResolverExecutionTask(解析所有GeneralResolver)
- 3.1添加被解析的Annotation的Matcher Check Task
- 4.执行MatcherCheckTask
- 4.1如果满足Scope就添加AddResolverExecutionTask
- 4.2不满足就走
- 5.执行AddResolverExecutionTask
- 执行3.1
- TaskQueue为空,中断Loop,返回Payload,将payload传递给下一个模块
v1.0 wep LinkCat v^0.x AnnotateService基本内容